-
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-TuningMachine Learning/Model 2024. 1. 20. 19:42
* [ACL 2021] "INTRINSIC DIMENSIONALITY EXPLAINS THE EFFECTIVENESS OF LANGUAGE MODEL FINE-TUNING" 논문을 한국어로 번역&정리한 포스트입니다.
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning (2021)
Armen Aghajanyan, Luke Zettlemoyer, Sonal Gupta
[ 논문 ]
Intro


LoRA : Low-Rank Adaptation of LargeLanguageModels
Pre-trained laguage models & Fine tuning
- PLM provide the defacto initialization for modeling most existing NLP tasks
- 어떻게 수백만 parameters 모델을 몇 천개의 데이터로 튜닝하는게 가능할까?
Number of parameters strongly inversely correlates with intrinsic dimensionality
- 모델의 parameter수가 많을 수록 intrinsic dimentionality 가 줄어듬.
- We Interprete pre-training as providing a framework that learns how to compress the average NLP task
- pretraining은 일반적인 NLP task를 함축하는 방법을 배운 framework를 제공하는 것으로 해석할 수 있음
요약
- Common NLP tasks within the context of pre-trained representations have an intrinsic dimension several orders of magunitutdes less than the full parameterization
- Intrinsic dimension = downstream task’s minimal description length
- process of pre-training implicitly optimizes the description length over the average of NLP tasks
- Larger models tend to have a smaller intrinsic dimension
- Compression based generalization bounds can be applied to our intrinsic dimension framework to provide generalization bounds for large pre-trained models independent of the pre-trained model parameter count
Intrinsic Dimension
Measuring the intrinsic dimension of object landscapes (ICLR 2018, Li et al)
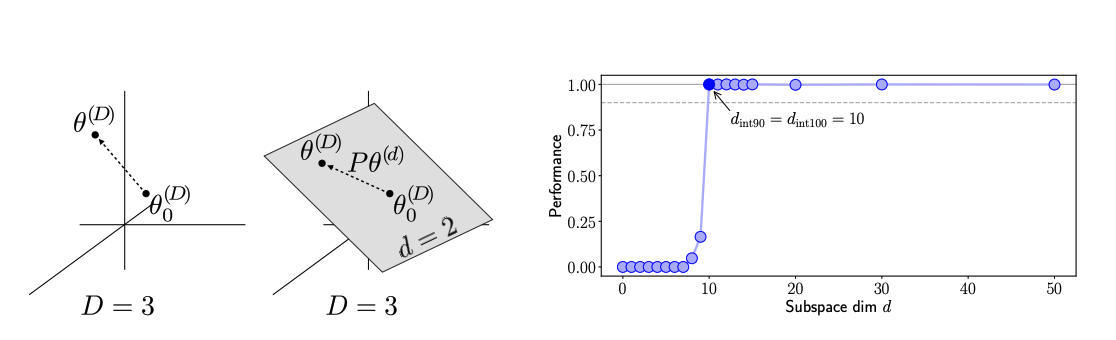
Definition
- The lowest dimensional subspace in which one can optimize the original objective function to within a certain level of approximation error.
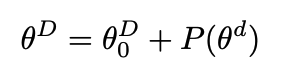
D = original model’s parameter d = lower dimensions parameter p = parameter projection D = original model’s parameter d = lower dimensions parameter p = parameter projection
- Li et al.(2018) propose the standard method of measuring the intrinsic dimensionality.
- seraching voer various $d$, training using standard SGD over the subspace reparamerization $\theta^D$ and selecting the smalllest $d$ which provides us with satisfactory solution
- satisfactory solution : 90% of the full training metrics
Parameter projections
- random linear dens projection $\theta^dW$
- random linear sparse projection $\theta^dW_{sparse}$
- random linear projectin via the Fastfood transform
$$ \theta^D = \theta^D_0 + \theta^dM, M = HG\Pi HB $$
The factorization of $M$ consists of
- $H$ = a Hadamard matrix
- $G$ = a random diagonal matrix with independent standard normal entries
- $B$ = a random diagonal matrix with equal probability ±1 entries
- $\Pi$ = a random permutation matrix.
- code
- def fastfood_torched(x, DD: int, param_list: Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, int]): """ Fastfood transform :param x: array of dd dimension :param DD: desired dimension :return: """ dd = x.size(0) BB, Pi, GG, divisor, LL = param_list # Padd x if needed dd_pad = F.pad(x, pad=(0, LL - dd), value=0.0, mode="constant") # From left to right HGPiH(BX), where H is Walsh-Hadamard matrix dd_pad = dd_pad * BB # HGPi(HBX) mul_2 = FastWalshHadamard.apply(dd_pad) # HG(PiHBX) mul_3 = mul_2[Pi] # H(GPiHBX) mul_3 = mul_3 * GG # (HGPiHBX) mul_5 = FastWalshHadamard.apply(mul_3) ret = mul_5[:int(DD)] ret = ret / \\ (divisor * np.sqrt(float(DD) / LL)) return ret
* eveyting is fixed, only $\theta^d$ paramters are trained
* matrix multiplication with $H$ can be computed in $\mathcal{O}(D\log{}d)$ via the Fast Walsh-Hadamard Transform
Structure Aware Intrinsic Dimension(SAID)
$$ \theta^D_{i} =\theta^D_{0,i} + \lambda_iP(\theta^{d-m})_i $$
- $m$ 개의 layer에서 각 layer별로 가중치 $\lambda$를 추가적으로 학습.
- 일반적인 fastfood transform 방식은 Direct Intrinsic Dimension(DID) 라고 칭함.
- code : https://github.com/rabeehk/compacter
Intrinsic dimensionality of common NLP tasks
- MRPC
- binary clasifcation
- prediction semantic equivalency for two paraphrases
- 3,700 training samples
- QQP
- binary classification
- predicting semanting equaility of two questions
- 363,000 training samples


Analysis
- with RoBERTa-Large, we can reach 90% of the full fine-tuning solution of MRPC using 200 parameters.
- RoBERTa consistently outperforms BERT across various subspace dimension $d$ while having more parameters.
- SAID method consistently improving over the structure unware DID method
Pre-Training and Intrinsic Dimension
- intrinsic parmeter vector = encodes the task at hand with respect to the original pre-trained representations.
- $d$ = minimal description length of the task with in the framework (dicteated by the pre-trained representation)
Hypothesis
- pre-training is implicitly lowering the intrinsic dimensionality of the average NLP task
- pre-training compress the minimal description length of the same tasks.
- generalization improves as the intrinsic dimension decreases
Pre-training intrinsic dimension trajectory

- retrain RoBERTa-Base from scratch and find intrinsic dimensionality
Analysis
- intrinsic dimensionality of RoBERTa-Base decreases as we continue pre-training.
- tasks that are easier to solve consistently show lower intrinsic dimensionality across all checkpoints.
- Yelp (sentiment analysis) vs ANLI ( Adversarial Natural Language Inference )
We argue that the large scale training of MLM learns generic and distributed enough representations of language to facilitate downstream learning of highly compressed task representations.
Furthermore, we argure for another persepective of pre-training learning representations that form a compression framework with respect to various NLP tasks.
Parameter count and intrinsic dimension
- MRPC dataset
- BERT, RoBERTa, BART, Electra, Albert, XLNet, T5, XLM-R with various sizes
- Strong general trend that as the number of parameters increases, the intrinsic dimension decreseas.
- Pre-training methodology becomes essential.
- in the regime of $10^8$ parameters, RoBERTa dominates similar sized pre-training methods
- There does not seem to be a method that can overcome the limitations induced by the # of parameters.

The more parameters we have in the model, the less we need to represent a task
Generalization bounds through intrinsic dimension

- Experiment with the connections between $d_{90}$ and evaluation set performance
- Lower intrinsic dimension is strogly correlated with better evaluation performance
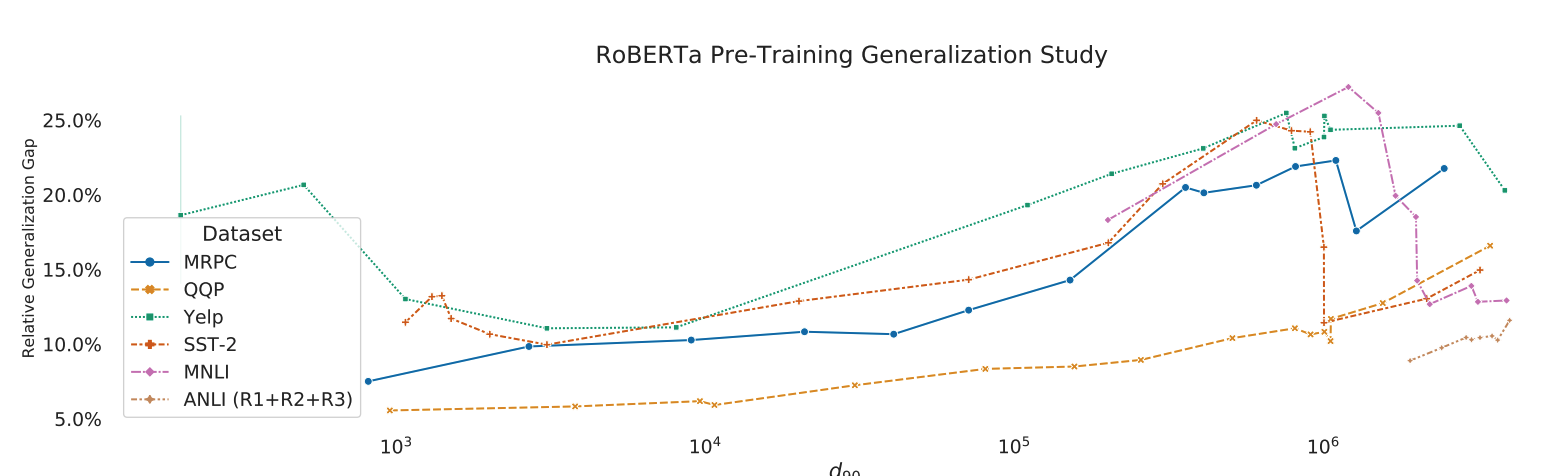
$$ generalization gap = \frac{acc_{train} - acc_{eval}}{1-acc_{eval}} $$
- Lower intrinsic dimension correlates strongly with a smaller relative generalization gap
Generalization Bounds
- Generalization is not necessarily measured by the pre-trained model’s parameter count or measure of complexity.
- but the pre-trained model’s ability to facilitate the compression of downstream tasks.
- → If we want to compress downstream tasks better, we must expect pre-trained representations to have a considerable measure of complexity

Conclusion
- Common natural language tasks could be learned with very few parameters, when utilizing pre-trained representations.
- Provide an interpretation of pre-training as providing a compression framework for minimizing the everage description length of lanugage tasks and showed the pre-training implicitly minimized this average description length.
📌 Intrinsic dimensionality is a useful tool for understanding the complex behaviour of large models.
'Machine Learning > Model' 카테고리의 다른 글
LoRA: Low-Rank Adaptation of Large Language Models (0) 2024.01.20