-
[Review] A Deep Reinforcement Learning Perspective on Internet Congestion Control - 인터넷 혼잡제어 관점에서의 강화학습Machine Learning/ETC 2019. 12. 30. 15:40
* [ICML'19] "A Deep Reinforcement Learning Perspective on Internet Congestion Control" 논문을 한국어로 정리한 포스트입니다.
참고 논문
N. Jay, N. Rotman, B. Godfrey, M. Schapira, A. Tamar, "A deep reinforcement learning perspective on Internet congestion control", Proc. 36th Int. Conf. Mach. Learn., vol. 97, pp. 3050-3059, 2019.
A Deep Reinforcement Learning Perspective on Internet Congestion Control
1. Introduction
1.1. Internet Congestion Control
- Multiple network users 가 부족한 통신 자원을 두고 경쟁한다.
- 네트워크 자원을 효율적으로 사용하기 위해 dynamic 하게 변조(modulate)돼야 한다.
-> Congestion Control ( CC, 혼잡 제어 )
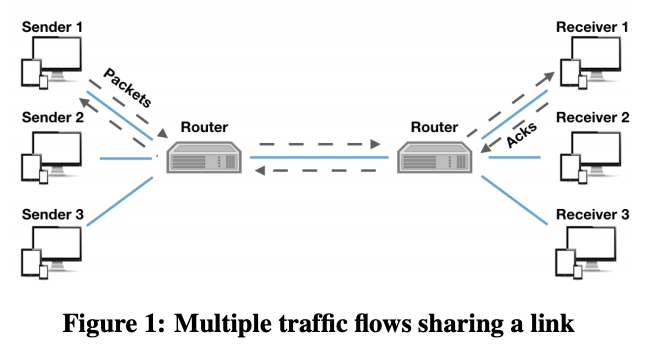
- multiple connections 이 single communication link를 공유하고 각 connection은 traffic sender와 traffic receiver로 구성된다. sender는 data packet을 보내고, recevier로 부터 packet acknowledgements (ACKs)라는 feedback을 지속적으로 받는다. sender는 이 feedback을 토대로 transmisson rate(전송률)을 조절하고, 조절하는 방식은 두 end points의 _congestion control protocol _에 의해 결정된다.
- 다른 connections들 간의 지속적인 상호작용은, connection들의 congestion control protocol, link의 capacity (bandwidth, 대역폭), link의 buffer size, packet queuing policy로부터 유래한 network dynamics(네트워크 역학)를 가능하게 했다.
- Congestion control에서, 다른 connectione들은 경쟁하는 connections에 대한 명시적인 정보 ( 숫자, entry/exit time, 시행되는 CC protocol ) 및 network에 대한 정보 ( link's bandwidth, buffer size, packet-queuing policy ) 없이 분산된, 조정되지 않는 방식으로 전송률을 선택한다. 또한 traffic이 다수의 links를 통해 전달되고, networks가 size, link capacities, network-latency, connections 간의 경쟁 수준 등이 달라지면서 CC에 대한 도전을 어렵게 만들고 있다.
1.2. Motivation RL-Guided Congestion Control
- Congestion Control에서 RL을 적용하는 것은 다음 두 관점에서 중요하다. 1) 인터넷 통신 구조의 중요한 부분의 성능을 향상함으로써 performance sensitive 한 모든 인터넷 분야에 영향을 줄 잠재력을 가지고 있다. 2) RL분야에 현실 세계에 적용 가능한 연구 과제를 제공할 수 있다.
- Congestion control protocol 은 receiver로부터의 받은 feedback의 history ( 과거의 traffic과 network condition을 나타내는)와 다음 sending rate 선택을 mapping 하는 것이다. 따라서 이러한 mapping을 RL을 통해 학습하는 것이 가능하다고 할 수 있다. RL을 통해 학습할 수 있는 패턴의 예시에는 다음 두 가지가 있다.
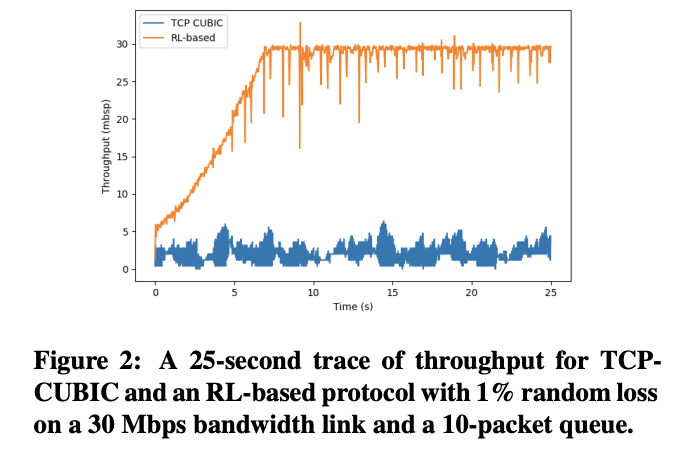
1) Congestion으로 인한 loss와 congestion이 원인이 아닌 loss를 구별하기.
- TCP cubic (Ha et al., 2008)은 발생하는 모든 loos에 대해 전송률을 절반으로 낮춘다. 하지만 RL-based protocol은 두 종류의 loss를 구별할 수 있다. 직관적으로, random loss는 sender의 action에 의해 영향을 받지 않지만, congestion에 의한 loss rate는 전송률이 증가함에 따라 증가하기 때문에 이를 학습하는 것이 가능하다.
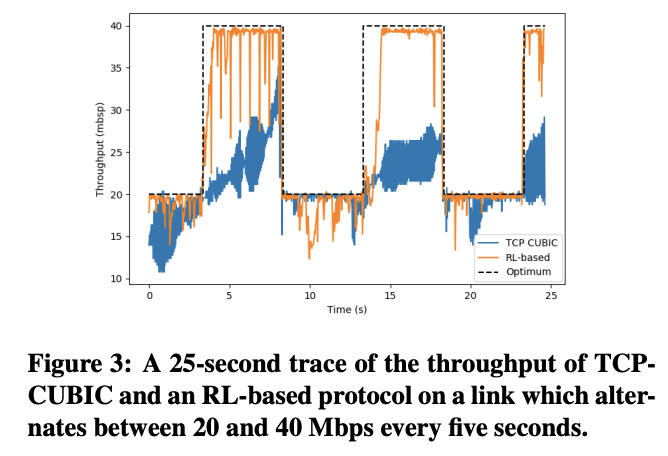
2) 다양한 network condition에 적응하기.
- network condition ( link capacities, packet loss rates, end-to-end latency)는 dynamic 하고 시간에 따라 크게 변한다 ( moblie/cellular network). TCP는 이런 다양한 network comdtions에 적응하는데 매우 나쁜 성능을 보인다. 위 그래프는 link capacity가 5초마다 20 Mbps, 40 Mbps를 오가는 환경을 나타내며, TCP Cubic 이 capacity를 효율적으로 사용하지 못하는 반면, RL을 적용한 방식은 optimum에 근접함을 알 수 있다. 직관적으로 RL protocol은 급격한 packet loss의 급격한 증가와 (bandwidth 20 Mbps), 20 Mbps를 넘는 전송률에서 손실이 발생하지 않는 경우 (bandwidth 40 Mbps)에 대해 학습할 수 있다.
1.3. Our contribution
- PCC (Dong et al., 2015; 2018) 방식을 확장한 RL-based congestion control 방식 도입. Aurora는 deep RL을 이용해 관측된 network 통계와 전송률 선택을 mapping 하기 위한 policy를 생성하며, 아주 단순한 simulation 환경에서 train 하는 것만으로도 복잡한 network domain에서 매우 잘 작동하는 CC policy를 생성하는 게 가능함.
2. RL Approach to Internet CC
2.1. Background: Reinforcement Learning
2.2. Congestion Control as RL
- Action - changes to sending rate
- States - bounded histories of network statistics
- MI $t$ 에서 sending rate $x_t$를 선택한 후, 전송 결과를 관측하고 statistic vector $v_t$ 를 ACKs로부터 계산한다. statistic vector는 다음 정보들을 포함한다.
- Latency gradient(PCC, Dong et al., 2015; 2018) : 시간에 따른 latency의 derivative
- latency ratio(RemyCC, Winstein & Balakrishman, 2013) : 현재 MI의 평균 latency와 모든 MI에서의 평균 latency의 최솟값의 비율
- sending ratio : 보낸 packet과 acknowleged 된 packet의 비율
- network는 사용 가능한 bandwidth, latency, loss rate에 따라 달라진다. statistics vector에 포함되는 요소들은 link 속성의 변화로 인해 connections 마다 크게 변하는 요소들을 배제함으로써 model의 일반성을 향상하고자 선택되었다.
- agent의 다음 전송률의 변화에 대한 선택은 고정길이의 history에 대한 함수이다. 가장 최근의 통계 대신에 고정 길이의 history를 고려함으로써 agent로 하여금 network conditions의 변화와 trend를 파악함으로써 더 적절하게 반응하도록 하였다. 따라서 각 time $t$에서의 state $s_t$ 는 다음과 같이 정의될 수 있다.
- $s_t = (v_{t-(k-d)}, ... , v_{t-d}),$
- $k$ 는 history의 길이, $d$ 는 모아진 결과와 sending rate 선택 사이의 delay이다.
- MI $t$ 에서 sending rate $x_t$를 선택한 후, 전송 결과를 관측하고 statistic vector $v_t$ 를 ACKs로부터 계산한다. statistic vector는 다음 정보들을 포함한다.
- Reward
- $ 10 * throughput - 1000 * latency - 2000 * loss $
- reward는 특정 application에서의 performace 요구에 따라 달라지는데, online game 같은 경우 매우 낮은 latency를 요구하는 반면, big file transfer는 높은 bandwidth가 더 중요하다. 어떤 서비스는 낮더라도 변동이 적은 bandwidth를 선호하는 반면에, bandwidth 변화가 심하더라도 더 높은 bandwidth를 요구하는 경우도 있다. action의 효과는 잠재적으로 즉각적이지 않은 결과를 야기할 수 있는데, RL에서는 이를 discount factor $\gamma$를 통해 조절한다. 이에 대해서는 3.3 절에서 자세히 다룬다.
2.3. Other Considered Approaches
- 다양한 형태의 congestion contol과 다양한 model 구조에 대해 고려해 보았는데, discount factor $\gamma$ 는 적어도 0.5 이상이 되어야 하며, 0.99에서 가장 좋은 성능을 보였다. 이는 task상에서 rewards가 제한된 버퍼 사이즈와 link occupancy의 증가로 인한 latency의 증가 등의 영향으로 지연되기 때문이다.
- linear model을 사용하는 것이 훨씬 안 좋은 performace를 보였다. ( 심지어 단순한 single layer neural network 보다 ). 또한 simple rand search와 hill-climbing for linear model (Mania et al., 2018)이 Continuos Mujoco tasks에서 더 잘 작동됨을 보였음에도 불구하고, 현재 환경에서는 적합하지 않았다.
3. Introducing Aurora : a specific implementation of RL for congestion control
3.1. Architecture

- $x_t = sending rate, \alpha = 0.025 $ oscillations (진동)을 줄이기 위한 scaling factor
- Neural network : two hidden layers, 32 -> 16 neurons, tanh nonlinearity
- Reward function
$ 10 * throughput - 1000 * latency - 2000 * loss $
$thorughput$ (pkt/second) $latency$ = (second) $loss$ = not ack / all pkt
3.2. Training - open-source gym environment (section 5)
- stable-baselines package PPO1 사용
3.3 Choice of Parameters
- History length $k$
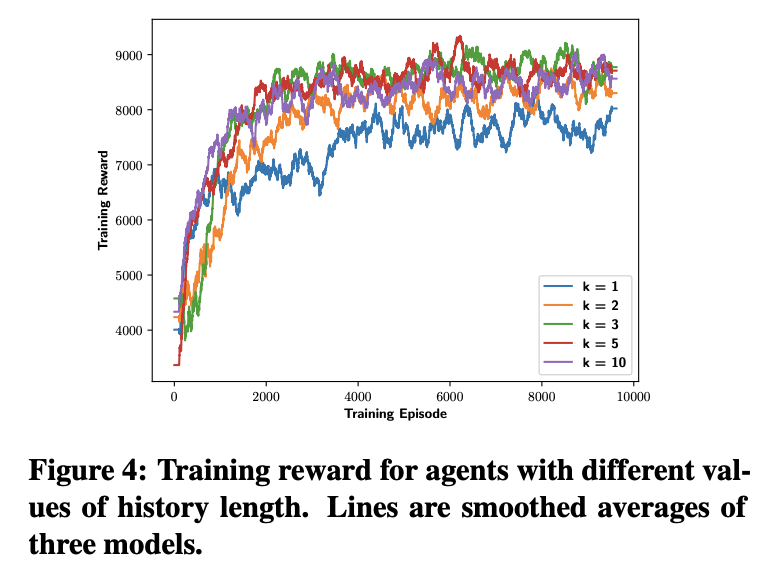
- Discount factor $\gamma$

4. Evaluation - Mininet (Fontes et al., 2015) and Pantheon (Yan et al., 2018) 사용
4.1. Robustness ( 견고성 측정)

- Figure 6 : bandwidth, latency, queuesize, random loss rate 네 가지 parameter 변화에 따른 modeld의 behavior 측정, 2분, single link, single sender 기준으로 TCP CUBIC ( CC 표준 ), PCC Vivace ( state-of-the-art algorithm)과 비교.
- Bandwidth sensitivity ( train 1.2 Mbps ~ 6 Mbps, test 1 Mbps ~ 128 Mbps, 보통 더 넓은 범위에서 작동해야 함. )
- Latency sensitivity ( train 50 ms ~ 500 ms, test 1 ms ~ 512 ms, 보통 더 낮은 latency를 가짐. ) : 1ms latency에서 낮은 성능을 보이는데, emulation environment에서 실제 packet을 처리하는 과정에서 1 ms 마다 noise가 추가되지만 training 시에는 존재하지 않기 때문이다.
- Queue sensitivity ( train 2 ~ 2981 packets, test 1 ~ 10,000 packets )
- Loss sensitivity ( train 0 % ~ 5 %, test 0% ~ 8% )
- Dynamic links ( 16 Mbs ~ 32 Mbps, mobile 환경과 같이 signal에 따라 capacity 가 변하는 환경 가정 )
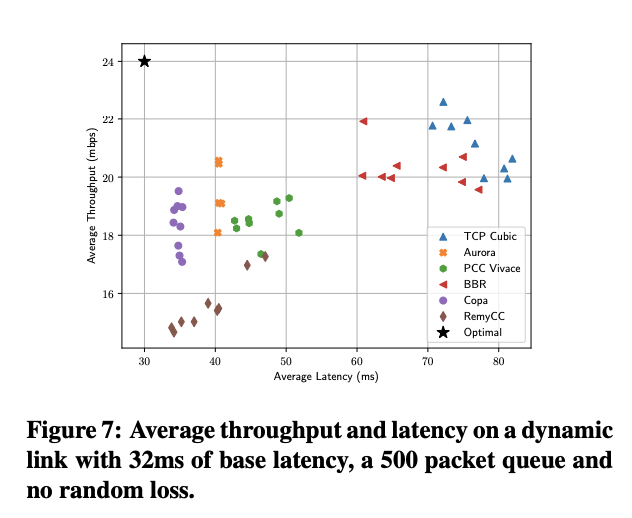
- Figure 7, TCP CUBIC 높은 Throughput but latency 도 높아짐. Aurora는 BBR과 비슷한 throughput을 보이지만 더 나은 latency를 보임. 최근의 디자인은 small web queries, video, gaming 등을 위해 더 낮은 latency를 추구하며 lower-latency 방법 중에 Aurora는 PCC-Vivace 보다 더 나은 throughput, lower latency를 보이며, RemyCC과 비슷한 latency에서 더 나은 throughtput을 보인다. Copa에 비해 4.2% 더 나은 throughput을 보이지만 latency는 16%가량 안 좋음.
4.2. Evaluation Summary
- training 환경보다 복잡한 환경에서 잘 동작하는 견고성(robust)을 보인다.
- state-of-the-art (BBR, PCC-Vivace, RemyCC, Copa)를 뛰어넘는 성능을 보여준다. 간단한 neural network 구조와 제한된 트레이닝 환경에도 불구하고.
5. A Tested for RL Congestion Control
현재의 networksimulator는 network의 복잡한 면 ( reachability, routing, packet header pasring )을 포함하지만, congestion control과는 연관이 적다. 이러한 이외의 특성들은 traing process를 느리게 하기 때문에, OpenAI Gym 기반의 환경을 제작하였다.
5.1. Links

Link 초기화 세팅 ( 위 범위에서 random하게 설정 ) - FIFO queue 기반에 Pantheon의 4가지 parameter 포함: bandwidth, latency, random loss rate, queue size.
5.2. Packets : tuple <senders, latency, is_dropped>
- sender : the route
- latency : what the sender will observe when an acknowledgement is returned
- is_dropped : if we shoul return an acknowledgement
5.3. Senders : agents with rate, route, list of observation

- rate = sender의 route에서 얼마나 빠르게 packet을 보낼지를 결정한다. route는 특정 시간에 고정되어 있고 sender는 observation을 만들어 ML agent에 전달한다.
- route = data 와 ACK가 traverse하는 list of links
- Figure 8 = list of the ovesravations. 이 paper의 gym 환경은 two links와 single Sender를 사용하며, 정해진 값 안에서 랜덤 한 bandwidth, latency, queue size, loss rate로 초기화된다. Sender의 sending rate는 bandwidth의 30% ~ 150% 사이에서 시작하며 action을 시작한다.
6. Remaining Challenges : 몇 가지 논의되지 않은 congestion control problem
6.1. Fairness
- Internet 상에서 많은 다양한 congestion control protocol이 상호작용하지만, Aurora는 몇몇 상황에서 unfairly 하게 행동할 확률이 높다. ( Remy의 global 최적화나, PCC의 내쉬 균형 분석도 사용하지 않음 ) 특히 TCP와 경쟁할 시, 때때로 packet loss를 발생시켜 TCP를 backoff 하게 해 network capacity를 사용하도록 학습하기도 하는 문제가 있다.
6.2 Multiple Objectives
- CC의 objective는 토론의 대상이며, 각 사용자는 다른 tradeoff를 선호한다. ( latency를 최소화 vs throughput 최대화 vs 다른 performance 기준). Multiobjective RL (Vamplew et al., 2011)은 다른 rewards들 사이의 tradeoff를 다루는 framework로써 적용이 가능하지만, 최근 Deep RL 연구는 이러한 방향으로 진행되지 않고 있다.
6.3. Generalization and Adaptation to Changes in the Network
- Aurora는 특정한 network 환경에서 train 한 후에도 더 넓은 범위에서 robust 하게 적용됨을 보여주었지만, generalization이나 transfer에 관한 부분에 대해서는 활발하게 연구가 진행중이며, training 범위를 벗어난 환경에서 test시에 더 나은 성능을 보장해 줄수 있을 것으로 기대된다.
- * tranfer learning? 비슷한 환경(source task)에서 학습된 결과를 다른 환경 (target task)에서 사용하는 것.
- 논문에서 인용한 Generalization, tranfer learning 논문
- Barreto, A., Dabney, W., Munos, R., Hunt, J. J., Schaul, T., van Hasselt, H. P., and Silver, D. Successor features for transfer in reinforcement learning. In Advances in neural information processing systems, pp. 4055–4065, 2017.
- Higgins, I., Pal, A., Rusu, A. A., Matthey, L., Burgess, C. P., Pritzel, A., Botvinick, M., Blundell, C., and Lerchner, A. Darla: Improving zero-shot transfer in reinforcement learning. arXiv preprint arXiv:1707.08475, 2017.
- Narasimhan, K., Barzilay, R., and Jaakkola, T. Deep transfer in reinforcement learning by language grounding. arXiv preprint arXiv:1708.00133, 2017.
- Tamar, A., Wu, Y., Thomas, G., Levine, S., and Abbeel, P. Value iteration networks. In Advances in Neural Information Processing Systems, pp. 2154–2162, 2016.
- network 환경의 변화를 detect 하는 방법
- Meta RL
7. Related Work
- Application of RL to highly specialized contexts
- Application of non-deep RL to Internet congestion control
- Deep RL 대신 SARSA 알고리즘을 사용하거나 (Kong et al., 2018), 최근에는 TCP NewReno의 변종으로서 적용을 위해 RL scheme을 적용하거나 Q-learning을 사용했다. (Li et al., 2016)
- Offline optimization of congestion control based on explicit assumptions about the network
- Congestion control via online-learning (multi-armed bandits)
8. Conclusion and Future Work
- Aurora, deep RL에 의한 congestion control protocol 은 제한된 training에도 불구하고 state-of-the-art에 필적하는 성능을 보여주었다. 또한 현실 세계 적용을 단순화하기 위한 중대한 challenges를 강조하였다.
- future work에서는 simulation software를 현실적인 부수적 data를 포함하고 multi-agent 의사 결정을 도입할 예정이다.
'Machine Learning > ETC' 카테고리의 다른 글
What is Congestion Control ( 혼잡 제어 )? (0) 2020.01.19 [Review] Pcc vivace: Online-learning congestion control. (0) 2020.01.08 [Review] Congestion-Control Throwdown (0) 2020.01.07 [Review] PCC: Re-architecting Congestion Control for Consistent High Performance. (0) 2020.01.05 Key papers in Congestion Control (0) 2019.12.30