-
[Review] Congestion-Control ThrowdownMachine Learning/ETC 2020. 1. 7. 17:02
* [HotNets'17] "Congestion-Control Throwdown" 논문을 한국어로 정리한 포스트입니다.
참고 논문
Schapira, M. and Winstein, K. Congestion-control throwdown. In Proceedings of the 16th ACM Workshop on Hot Topics in Networks, pp. 122–128. ACM, 2017.
Congestion-Control Throwdown
Michael Schapira, Hebrew University of Jerusalem; Keith Winstein, Stanford University.
[ 논문 ]
* Throwdown 스로다운 ((미식축구에서 심판이 공을 양 팀 사이에 떨어뜨려 게임을 재개시키는 일)), 논쟁이라는 의미로 해석해도 될 것 같다.
* Hamilton 역할을 맡은 Schapira는 PCC의 저자이며, Burr 역할의 Winstein은 Remy의 저자이다.
Abstract
- Congestion Control ( CC, 혼잡 제어 ) 는 네트워크 연구의 중요 주제로써, 누가, 언제 데이터를 보내는지 결정하는 과정에서 경쟁하는 사용자와 어플리케이션 사이에서 한정된 communication 자원을 어떻게 분배할지를 결정하고 collapse 를 막는 역할을 혼잡 제어가 수행하게 된다.
- 분야에 대한 연구는 활발히 진행되고 있으며, 30여년 간의 연구에도 불구하고 기본적인 원칙에 대한 논의가 진행되고 있다. 이 논문에서 두 저자는 혼잡제어의 근본적인 교리에 대해 서로 마찰을 빚고 있다. ( at loggerheads )
1. Introduction
- Hamilton 과 Burr 은 학회 참석후 서로 집으로 돌아가는 비행기에서 옆자리에 앉은 것을 발견하고, 서로가 가진 혼잡제어에 대해 토론해 보기로 한다.
2. Hamilton's Opening Statement
2.1 Remy vs. PCc vs. BBR
- Remy 는 input을 네트워크에 대한 명시적 가정 ( wire speed의 범위, RTT, bottleneck link의 sender 수, Designer 의 글로벌 최적화 목적 즉 비례하는 fairness ) 으로 간주한다. Remy 는 이를 통해 네트워크의 model을 생성하고 관측한 네트워크 state ( 패킷의평균 ACK, 현재 RTT와 최소 RTT의 비율 등 ) 와 제어 행동 ( congestion window의 크기를 곱하거나, 더하는 것)간의 좋은 함수 관계를 추구한다.
- BBR은 network pipe를 하나의 링크로 model화 하여, 반복적으로 대역폭, RTT를 관찰하여 bottleneck link의 bandwidth를 추적한다.
- PCC는 연속적으로 전송을 local한 성능 목표를 나타내는 untility value와 연관 짓는다. 이는 경험한 성능 관련 통계 ( Goodput, loss rate, latency )를 모아 특정한 값으로 변환하는 utility function 에 의해 이루어 진다. PCC의 제어 알고리즘은 전송률을 경험적으로 더 나은 utility를 생성하는 쪽으로 맞춘다.
- 네트워크 모델에 의존하는가? : Remy는 네트워크에 대한 선험적 가정 ( a priori assumption ) 을 입력하여 네트워크 model 을 생성하며, BBR은 online으로 네트워크 pipeline 모델을 생성한다. PCC 는 네트워크 모델에 의존하지 않는다. Remy와 BBR은 white-box 접근법이며, PCC는 black-box 접근법이다.
- Global vs. local 최적화 : Remy는 global 최적 값에 도달하고자 하며, BBR 과 PCC는 local 성능을 최적화 한다.
- 나는 다양한 네트워크 환경과 wild Internet 상에서 견고하게 ( Robustly ) 높은 성능을 달성하는 전송 제어를 디자인 하는 일은 받아들이기 힘든 진실을 받아들이는 것을 포함한다고 주장한다.
2.2 Generating an accruate network model of the Internet might not be feasible
- 인터넷 환경은 white-box 접근 방법을 사용하기에는 지나치게 복잡하다. traffic flow는 나갔다 들어오고, 네트워크 디바이스나 링크는 fail할 수 있으며 패킷은 다른 커뮤니케이션 media, 그룹, 수많은 hop을 통과하며, 다른 종단 host들은 서로 다른 전송 제어 프로토콜을 사용하고, 지연율 증가와 패킷 손실이 혼잡이 아닌 microbursts나 물리 계층 corruption으로 인해 발생하기도 한다.
- 이러한 복잡성은 네트워크 모델이 부정확해지는 원인이 되고, 모델과 현실의 차이에도 불구하고 실제로 white-box 접근법이 잘 동작하는 이유에 대해 주장하기 위해 결국 경험적인 증거로 회귀할 수 밖에 없다.
- black-box 접근법은 어떠한 모델도 만들지 않으며 경험적으로 측정한 성능과 전송률 변화와의 좋은 함수를 추구한다. 나는 이러한 디자인 철학이 다양한 네트워크 환경에서 더 좋은 견고성을 제공할 것이라 믿는다.
2.3 You cannot reach a global optimum at Internet scale
- 각기 다른 어플리케이션은 다른 성능 요구사항을 가지고 있고, 이는 전송률 제어 프로토콜 입장에서는 알 수 없다. 심지어 올바른 global 최적화 목표에 대해 정의하는 것도 명확하지 않다. 그러한 개념이 존재한다 하더라도, 목표 함수를 최적화 하는 것은 모든 종단 호스트들이 미리 정의된 프로토콜을 사용하고 traffic flow가 global 최적화가 의미있을 만큼 오랜 기간 지속된다는 가정에 의존하고 있다.
- 나는 명백한 global 네트워크 성능 최적화를 포기하는 것은 불운한, 그리고 피할수 없는 인터넷의 복잡성의 결과라고 생각한다. 대신에 전송률 제어 프로토콜은 다른 목적, 지역 성능 최적화나 병목 링크에서의 공정성, 균형으로의 빠른 수렴, 남는 용량의 빠른 utilization 등과 같은 목적에 집중해야 한다고 생각한다.
2.4 Rate-control via online learning is a promising direction
- 앞서 언급한 3가지 전송률 제어 방식중 유일하게 PCC 만이 black-box 방식을 사용하고 global 성능 최적화를 추구하지 않는 방식이다. PCC ( 2015년 버전 )는 다음 세대 혼잡제어를 위한 약속된 패러다임이라고 믿지만, 구체적인 구현은 아직 잠재력을 다 발휘하지 못했다.
- 내가 생각하는 연구 방향은 다음과 같다. 학습 이론과 게임이론의 online learning 연구의 아이디어와 기술을 전송률 제어에 도입하는 것이다. onlne learning ( no-reger learning ) 은 불확실성 속에서 의사결정을 하는 유용한 개념을 제공한다. 의사 결정자는 선택 가능한 전략 중 행동을 지속적으로 선택하고. 의사 결정자는 전략의 결과, utility value로 표현되는 값을 오직 전략을 선택한 후에야 알 수 있다. 이러한 online-learning 기법은 전송률을 제어하는데 적절하며, 환경의 완전한 불확실성 속에서도 증명된 보증 ( no regret ) 을 제공한다. 즉, 전략의 선택과 그로 인해 야기된 utility 값의 관계에 대해서는 어떠한 추측이나 해석도 하지 않는다. 또한 online learning algorithm은 함께도 잘 동작하며, 적절한 환경에서 online learning을 적용하는 다수의 의사 결정자들 사이에서 안정된 결과로의 global convergence 또한 보장된다.
- 전송률 제어는 쉽게 online learning 문제로 치환될 수있다. traffic snder는 전송률을 선택하고 충분히 기다린 후 그 전송률에서의 성능을 결과로써 배운다. PCC의 utility function에 대한 즉각적인 선택 대신에 online learning 이론 기반의 원칙에 입각한 접근법을 사용해야 한다. 최근의 실험 결과들은 state-of-the-art online learning 기반 전송률 제어가 TCP, BBR, PCC의 구현을 다양한 환경에서 성능 면에서 능가한다는 것을 보여주었다.
3 BURR SPEAKS IN OPPOSITION
- 우리 사이의 의견차이에도 불구하고, 나는 비행기의 옆자리에 앉을 수 있는 더 나은 동료를 바랄 수 없다. 하지만 당신의 관점은 내게 그렇게 타당하게 보이지 않는다.
3.1 Local optimization = lousy outcomes
- PCC의 혁신적인 점은 각각 flow가 online 최적화를 시행한다는 것인데, 이는 인간이 offline으로 좋은 혼잡 제어 알고리즘을 디자인 하기위해 노력했던 전통적인 TCP 혼잡제어 (NewReno, Vegas, FAST, Cubic, RemyCC 등 ) 과 구별되는 점이다. PCC 는 online 으로 최적화가 진행되기 때문에, 목적 함수는 필연적으로 locally 인식가능한 입력 ( sending rate, throughput과 같은 ) 을 포함할 수밖에 없다.
- 내 관점에서, 지역적으로 인식가능한 utility function의 분산된 hill-climbing 방식은 혼잡제어의 적절한 기초라고 할 수 없다. 다음 그림과 같은 예시를 보자
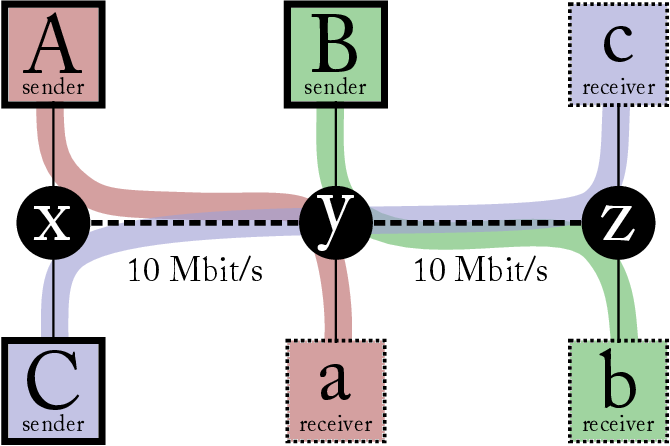
- 위와 같은 예에서 flow가 어떻게 나눠져야하는지에 대한 맞는 답은 없다. 파레토 최적에 맞는 공정한 답이 있을 뿐이다. max-min fair한 답은 A B C가 각각 5 Mbit/s 를 할당받는 것이고, 비례적으로 공정한 답은 C 가 두배 많은 flows of cross=traffic을 가지고 경쟁한다는걸 기반해서 A와 B의 절반에 해당하는 값을 할당하는 것이다. 또는 A와 B에 10을 C에는 아무것도 주지 않는 max-total throughput 해결책도 있다.
- 각각의 해결책은 다양한 utility function에서 global 총합을 최대화 하는 것과 연결된다. 비례적으로 공정한 해결책은 $\log A + \log B + \log C$를 최적화하는 식이다. 따라서, 지역적으로 각자의 utility function을 최적화 하는 것은 타당하지 않은데, 목적 함수가 $\log (throughput)$ 일 경우 더 높은 점유율을 위해 가능한한 빠르게 전송하고자 시도할 것이고, 경쟁하는 flow가 더 빠른 전송을 시도한다면, 스스로도 전송률을 지키기 위해 전송 률을 높여야 한다. "online" 최적화의 비극은 여기서 시작된다.
- 물론 당신은 PCC의 목적함수는 이와 같이 동작하지 않으며, PCC의 목적함수가 많은 loss에 대해 페널티를 주기 때문에 위와 같은 무차별적 전송은 발생하지 않을 것이라 할 것이다. offline 기반의 좋은 혼잡 제어 디자인에 대해서는 잊어버리고, 단순히 목적 함수를 설정하자는 것은 매력적인 제안이다. 많은 노력이 이러한 offline 방식을 디자인하는데 들어갔고, online 방식으로 이를 대체할 수 있다면, 이는 멋진 일이다.
- 하지만 내게 그것은 너무 야심찬 생각으로 보인다. 위와 같은 단순한 네트워크에서도 말이다. 0 ~ 11 Mbit/s 의 랜덤한 초기 전송률을 가진 3개의 flow를 대상으로 위와 같은 환경에서 실험하였을 때, 각 flow는 목적 함수에서 더 이상의 개선이 되지 않을 때까지 전송률을 조절하며, 이러한 과정은 세 전송률이 어떠한 고정된 점에 도달할 때까지 지속된다.
- 좋은 소식은 PCC가 항상 어떠한 안정된 전송률의 할당으로 수렴한다는 사실이고, 나쁜 소식은 초기 전송률이나 flow의 시작 순서에 따라 할당이 넒은 범위에서 이루어진다는 사실이다. 수렴한 결과는 값에 상관없이 분산된 지역 최적화에서의 고정된 지점이다.

- 합리적인 사람이라면 자원의 할당에 올바른 답이란 없다고 주장할 테지만, 나는 "어떤 flow가 먼저 시작됐는지"와 같은 요인에 의해 변하는 것이 좋은 방식이라는 사실에는 동의할 수 없다. 여기서의 문제점은 각각의 flow가 다른 flow의 상태에 대해서는 알지 못하며, 자신의 throughput만을 볼 수 있다는 사실이다. 또한 한번 안정된 상태가 되면, 더 이상의 손실은 발생하지 않고 어떠한 흥미로운 혼잡 신호도 존재하지 않게 된다. 각각의 flow는 후회할 어떠한 이유도 없으며 ( 각 flow 에게 개별적으로 더 나은 전송률이란 존재하지 않는다 ) no-regret learning에 대한 주장은 중요한 사실로부터 관심을 돌리려는 시도로 보인다.
- Burr's conjecture : 중앙화 되지 않은 혼잡제어 방식이 만약 greey 하게 그 스스로의 traffic의 운명을 input으로 최적화하는 이상 "멍청한" 병목링크 ( Droptail queue와 같은 )에서 globally하게 점근적으로 안정화 되는 것은 불가능하다.
- 좋은 혼잡제어 알고리즘이 존재하지 않는다는 뜻은 아니다. 내가 말하고자 하는 바는 좋은 알고리즘은 단순히 지역적으로 인식가능한 목적 함수를 최적화 하는 방식보다는 더 정교하게 행동해야 한다는 뜻이다. 좋은 방식은 exploitation ( 현재 상태 ) 와 exploration ( 현재의 행동이 다른 traffic을 해할 가능성이 있다면 단기적으로 개인의 이익에 반하는 행동을 하는 것 ) 의 균형을 유지해야 한다. 이러한 알고리즘을 디자인 하는 곳은 바로 offline이다.
- AIMD 방식 ( 멍청한 방식 중 가장 멍청한 방식) 또한 exploration 과 exploitation 행동을 보이며 이상적인 PCC 보다 더 훨씬 나은 결과를 보인다. flow 가 어떤 순서로, 어떤 전송률에서 시작하는지와 무관하게. 멍청한 방식은 설계된 -offline- 대로 행동하며, 임의로 도착하는 flow에서도 전체적으로 좋은 결과를 만들어 낸다.
- 핵심은, 혼잡 제어 방식이 독자적으로 locally 인식 가능한 목적 함수를 최적화 한다고 해서, 목적 함수가 공유지의 비극을 유도하지 않도록 설계된다고 해서, 그리고 그 방식이 특정한 전송률을 할당받도록 수렴하고 그 과정에서 모든 flow에게 후회할 이유가 없다고 해서 우리가 그 방식을 좋다고 할 수는 없다는 것이다. ( 모든 flow가 점점 더 나은 결과를 얻어가며 수렴한다고 해서, 그 값이 global 하게 최적화된 값은 아니다 )
3.2 Every scheme embodies assumptions about the network
- online 기법을 제안하는 사람들은 그것이 현실적인 환경에서 더 잘 동작한다고 증명하며, 만약 당신이 내 고전적인 parking-lot 예시가 적절하지 않다고 생각한다면, 우리의 논의는 아마 현실적인 환경이 무엇인가에 대한 주장을 포함해야 할 것이다. 그리고 그 주장은 모델과 가정을 포함한다!
- 왜 멍청한 방식을 사용하지 않을까? 현실에서, flow는 나갔다 들어오고, 수렴하는데 걸리는 시간은 매우 중요하다. AIMD 방식은 long term 에서 공정한 할당을 훌륭하게 해내지만, 빠르게 수렴하는데는 좋지 못하고, 새로운 flow를 받아들이는 데에는 최악이다. 이러한 constant ( 설계 과정에서 포함되는 상수 ) 는 디자이너의 네트워크와 시나리오에 대한 기대를 포함한다. 얼마나 빨리 flow가 들어와서 나갈 것인가? vs 오래 지속되는 flow 가 잘 동작하는 것은 얼마나 중요한가?
- PCC 또한 네트워크에 대한 디자이너의 가정을 수행한다. 목적 함수는 손실이 유용한 혼잡의 신호라고 가정하며, 0.05의 상수는 stocastic한 손실이 5%보다 작을 것이라고 가정한다. 만약 이러한 가정이 틀리게 되면, PCC의 성능은 떨어진다. 손실이 없는 deep-bufferd bottleneck에서 PCC는 잘 동작하지만, 너무 많은 확률적 손실이 지나치게 큰 link에서 PCC는 아무것도 할 수 없다.
- 이러한 상수를 조작하는데는 어떠한 문제도 없지만, 결국 상수는 그 방식이 마주하게될 상황과 작업에 대한 누군가의 기대를 나타낸다. "어떠한 네트워크 모델도 높은 확률로 부정확하다"는 당신의 말은 사실일지 모르지만, 이 말은 모든 혼잡 제어 방식 ( 아마도 모든 설계된 시스템 ) 에 똑같이 적용되는 말이다. TCP Tahoe와 같은 방식은 90년대의 많은 flow가 있는 작은 버퍼에서 잘 동작했지만 2000년대의 "bufferbloat" 환경에서는 잘 동작하지 않았다. 바뀐것은 내재된 가정과 실제로 마주친 네트워크의 관계이다.
- 전체 인터넷을 모델링하는 것은 불가능하다는 지적은 옳지만 그에 대한 증거는 없다. TCP Tahoe 는 단순한 모델임에도 오랜기간 잘 동작했다. Remy는알고리즘과 모든 상수를 생성하는 설게 도구의 구조적 형식에 대해 명시함으로써 디자이너로 하여금 그들의 가정을 구체화하도록 강요하는 노력을 보여주었다. 모델이 어떻게 표현되는지에 따라, Remy는 멍청한 방식들을 통합할 수 있다.
- PCC가 모델과 가정에 대해 더 명백하지 않다고 해서, 그것에게 모델과 가정이 없다는 뜻은 아니다. 내 관점에서, 진짜 구분점은 네트워크 모델에 대한 의존이나 가정의 존재가 아닌, 그러한 가정이 명시되어 있는지, 프로토콜의 행동이 가정과 목표의 함수로 정당화될 수 있는지의 여부이다. 만약 당신이 다른 종류의 네트워크에 대해 알고리즘을 tuning하고자 한다면 ( PCC 내용 ) 그것은 PCC 깊은 곳에 네트워크에 대한 가정을 전제로 한다는 신호로 보인다.
- 당신은 PCC 가 모델에 의존하지 않고 네트워크 환경의 다양성에 대해 견고성을 보인다고 할지 모르지만, PCC 가 50%의 랜덤 손실을 보이는 네트워크에서 어떻게 동작할 것인가?
4 HAMILTON REPLIES
4.1 White-box vs. black-box approaches are inherently different design philosophies
- 어떠한 접근법도 네트워크에 대한 모델을 반영한다는 사실에는 동의할 수 없다. 그리고 이 사실은 중요하다.
- 이미지에서 고양이를 구분하는 비유에 대해 생각해보자. 한 가지 접근법은 '고양이가 무엇인가'( 고양이는 뾰족한 귀와 날카로운 이를 가지고 있다. )에 대한 명시적인 모델을 가지고 모델에 기반한 결정을 내리는 것이다. 다른 접근법은 기계학습을 적용하는 것이다. 기계학습적 접근법에서는 결정이 '해석 가능할' ( 고양이의 모델이 neural network로 부터 reverse engineering이 가능하다 ) 필요가 없다. 실제로 대부분의 정확한 ML 접근 법은 그렇게 하지 않는다.
- 왜 이 사실이 중요한가? 컴퓨터 비전을 포함한 Computer Science의 다른 주요 분야에서, 복잡한 현상의 정확히 설명가능한 모델에 기반한 결정을 내리고자하는 열망을 포기하는 것은 state-of-art를 넘어서는데 중요하다는 사실이 증명되어왔다. 어떠한 상황에서는 white-box approach가 좋다고 할지 모르지만, 일반적으로 black-box approach, 즉 경험적 증거에 기반한 접근법이 더 나은 성능을 보인다.
- rate control로 돌아가서, Online-learning에 기반한 rate-control은 위의 고양이에 대한 예시와 똑같은 black-box 접근법을 반영한다. 이는 결정의 기반을 network에 대한 모델에 두고 있지 않으며, 대신 rate를 과거의 rate 선택으로부터 경험적으로 관측된 결과에 기반하여 결정한다. PCC Allegro의 결과를 포함한 black-box 접근법은 rate control 부분에서 더 나은 성능을 보임을 보일수 있다. 또한, 다른 ML 테크닉과 달리, online learning은 증명가능한 성능 보장이 포함되어 있다.
- One size to fit them all? 나는 하나의 black-box 접근법이 모든 네트워크 환경에서 최적의 값이 될 수 있다고 주장하는 건 아니다. 나는 utility function과 online algorithm의 선택에 따라 다른 환경에서 다르게 잘 동작할 것이라 기대한다. online-learning 방식을 선택하는 것은 설계자의 목표에 따라 달라져야 하고, 경험적이고 이론적인 탐구에 의해 안내되어야 한다. 나는 online-learning 방식이 가까운 미래에 다른 네트워크 환경에 적용되기를 바라고, 특정 상황에 맞게 설계된 white-box approach봐 더 나은 성능을 보일 수 있을 것이라 생각한다.
- 즉 rata-control에 대한 black-box 접근법을 통해, 더 견고한 방식으로 높은 성능을 제공할 수 있을 것이며, 특수한 protocol을 수없이 만드는 일을 피할 수 있을 것이다.
- 나는 네트워크 모델을 design 철학으로써 의존하는 것에 대해 의문을 제기하기는 하였지만, 물론 네트워크 모델은 rate-control을 분석하는데 필수적인 요소인 것은 분명하다.
4.2 Optimizing in wonderland?
- 예시로든 parking-lot 상황에서, 모든 세 flow는 오랜 기간 지속되고 같은 프로토콜을 사용하며, 모든 링크는 패킷을 비례적으로 손실시키며, 다른 flow는 중간에 떠나거나 들어오지 않으며, link는 fail하지 않고... 그 외에 많은 가정을 포함한다. 또한 당신은 최종적으로 근사하는 안정된 상태로 당신의 관심을 제한하고 있다. 나는 이러한 가정이 일반적인 white-box approach에 깔려있다고 생각한다. 당신이 상상하는 네트워크 모델보다 더 많은 일들이 실제로 일어난다.
- 충분히 안정적이고 예측가능한 네트워크에서 rate-control을 최적화 하는 것은 타당하고, 최적값에 대한 개념은 분명하다. 특정한 환경을 제외하고, 위와 같은 상황이 발생할 수 있을까? 내 대답은, 일반적으로 "아니오"다.
- "Burr's conjecture"가 사실인지 아닌지는 요점에서 벗어나 있다. 요점은 global 최적화 framework는 내재된 가정이 깨지는 순간 실패한다. 즉, 어떤 연결이 다른 프로토콜을 사용하고, 어떤 router가 다른 queueing policy를 사용하는 경우가 발생하는 경우에 말이다. 이 사실이 다른 목적과 개념적인 framework에 대한 필요성을 제기하는 것이다.
4.3 What's next?
- 당신이 지적한 PCC의 특성은 online-learning 방식의 문제가 아니라, PCC Allegro의 구체적인 구현의 문제로 보인다. 올바른 알고리즘과 utility function을 찾는 것은 개념적으로 매력적이고 실용적으로 신뢰할만한 연구 주제이다.
5 BURR'S CONCLUSION
- Hamilton, 나는 30년 이상 연구가 진행된, 아마 쐐기 문자이후 가장 중여한 통신 매체일 이 분야를 흔들고자 하는 당신에게 경의를 포한다. 우리의 의견차이를 정리해보자면 다음과 같다.
- The "white-box vs. black-box design philosophy" issue 는 당신에게 중요할지 모르지만, 내겐 중요하지 않다. 아마 당신은 BBR이나 Remy, 심지어 Reno 또한 오만한 방식이라 생각할 것이다. 그들은 네트워크가 어떻게 행동할지에 대한 의견을 품고있다. Reno는 손실이 과부하를 뜻한다 가정하기 때문에 손실 발생시 window를 반토막 낸다. BBR은 손실이 bottleneck bandwidth와 rate를 나타낸다고 가정한다. Remy는 설계자가 모든 상황을 사전에 모든 가정을 명시하기를 원한다. 반면에 단순이 rate를 올리고 내림으로써 flow를 최적화하는 목적함수를 가지는 것은 더 정제된 방식으로 보인다.
- 내게는 디자인 철학은 요점에서 벗어나 있다. 설계자가 생각하는 것은 관련이 있지 않다. 내가 신경쓰는 것은 코드가 어떻게 동작하는지이다. 모든 방식은 잘 동작하는 상황이 있고, 잘 동작하지 않은 상황이 있다. 이는 궁극적으로 방식의 네트워크에 대한 가정을 나타낸다고 생각한다. 나는 online-최적화가 다양한 시나리오에서 더 나은 성능을 보인다는 증거가 있다고 보지 않는다.
- 당신은 더 원칙적인 learning method를 기대하지만, 나는 확신할 수 없다. 어떠한 flow도 regret하지 않는 상황에서도 문제가 발생함을 parking lot 네트워크는 보여주었다. 그렇기에 나는 이것이 우리에게 필요한 것인지에 대해서는 회의적이다.
- 혼잡제어에 대한 이론이 여전히 필요할까? 우리가 논하지 않은 것은 BBR의 발생이다. 이 방식을 개발하기 위해 구글은 회사 트래픽을 통해 많은 실험을 돌려보았다. 그들이 구글의 실제 트래픽을 이용해 BBR을 디자인하고 metrics를 최적화 한 것은, 돈과 연관되어 있다. 그들과 같은 선상에서 서는 것에 대해 회의적일 수밖에 없는 이유는, 우리가 가지지 못한 데이터를 그들이 가지고 있기 때문이다. 인터넷 트래픽이 적은 수의 big player에 의해 오는 세상에서, 누가 자신감있게 그들의 길을 갈 수 있을까? 우리가 한 논의나, 이론이 할 수 있는 역할이 아직 있을까?
'Machine Learning > ETC' 카테고리의 다른 글
What is Congestion Control ( 혼잡 제어 )? (0) 2020.01.19 [Review] Pcc vivace: Online-learning congestion control. (0) 2020.01.08 [Review] PCC: Re-architecting Congestion Control for Consistent High Performance. (0) 2020.01.05 [Review] A Deep Reinforcement Learning Perspective on Internet Congestion Control - 인터넷 혼잡제어 관점에서의 강화학습 (0) 2019.12.30 Key papers in Congestion Control (0) 2019.12.30