-
Human Feedback is not Gold StandardMachine Learning/MLLM 2024. 11. 28. 19:52
https://openreview.net/forum?id=7W3GLNImfS

1. Introduction
- Open-ended generation tasks에서 인간 평가는 사실상 표준이 됨
- 인간 평가는 절대 점수일수도(1~5), 두 응답간의 비교가 될 수도 있음
- 인간 평가자는 주어진 과제를 더 쉽게 하기 위해 shortcut을 찾는 경향이 있음
- fluency, linguistic complexity와 같은 피상적인 요소에 기반하여 평가함
- factuality와 같은 더 많은 노력이 필요한 요소는 간과됨
- 인간 평가를 종합 점수 / 특정 오류 기준에 대해 분석
2. Are preference score reliable?
Error Types

- 유해성, 유창성, 범위, 반복, 거부, 형식, 관련성, 사실성, 불일치, 모순
Error Annotation Instruction
- Inconsistency with Request (요청과의 불일치)
- Does the response incorrectly represent or change information provided in the request?
- 응답이 요청에 제공된 정보를 잘못 나타내거나 변경했습니까?
- Self-Contradiction (자기 모순)
- Is the response internally inconsistent or does it contradict itself?
- 응답이 내부적으로 일관성이 없거나 스스로를 모순합니까?
- Factuality (사실성)
- Is the response factually incorrect? (Use reliable sources like Wikipedia or Google to verify any included facts.)
- 응답이 사실적으로 잘못되었습니까? (포함된 사실을 검증하기 위해 Wikipedia나 Google과 같은 신뢰할 수 있는 출처를 사용하세요.)
- Relevance (관련성)
- Does the response go off-topic or contain information that is not pertinent to the request?
- 응답이 주제에서 벗어나거나 요청과 관련 없는 정보를 포함하고 있습니까?
- Formatting (형식)
- Does the response fail to follow any specific formatting or length requirements outlined in the prompt?
- 응답이 프롬프트에 명시된 특정 형식이나 길이 요구 사항을 따르지 않았습니까?
- Refusing Reasonable Requests (합리적인 요청에 대한 거부)
- If the request is reasonable, does the response refuse to answer? (A low-quality attempt to respond is acceptable. If the request is unsafe or impossible, refusal is allowed.)
- 요청이 합리적임에도 응답이 이를 거부했습니까? (저품질의 응답 시도는 허용됩니다. 요청이 위험하거나 불가능한 경우 거부가 허용됩니다.)
- Repetition (중복)
- Does the response unnecessarily repeat information? (e.g., repeated items in a list or phrases used multiple times).
- 응답이 불필요하게 정보를 반복하고 있습니까? (예: 목록에서 항목이 반복되거나 동일한 문구가 여러 번 사용되는 경우)
2.1 Experimental setup
- 각 모델 출력이 오류 유형에 해당하는지 아닌지 (y/n)
- 모델 출력의 전반적인 품질 (1~5, 자신이 중요하다고 느끼는 기준에 따라)
Dataset
- Curation Corpus (Curation, 2020)
- Amazon Product Descriptions (Ni et al., 2019)
- Wikihow (Koupaee & Wang, 2018)
Model
- MPT 30B
- Falcon 40B
- Command 6B and 52B
2.2 Results
Preference scores under-represent factuality and inconsistency
- 선호도 점수는 사실성과 불일치를 대표하지 못함
- 10가지 요소중 6가지가 종합 점수에 기여함
- 기여하지 않은 유형은 실제로 잘 나오지 않은 유형임 ( 출력의 1% 미만)
Annotators struggle with disentangling factors
- Distractor Example:
- 동일한 모델이지만 다른 input을 사용한 출력
- fluency, detail, factuality에서는 비슷한 점수를 받아야하며, releavance나 전체적인 점수에 있어서 s낮은 점수를 받아야함
- Figure 2: Contradiction과 Factuality와 같은 요소들이 잘못된 벌점을 받음
- 평가자들이 이러한 기준을 전체 품질과 분리하는데 어려움을 겪음
- 평가자들은 첫인상에 기반하여 출력에 대한 의견을 무의식적으로 형성하고, 이 의견이 각 오류 유형에 대한 판단에 영향을 미침
3. Are annotations affected by confounders?

3.1 Assertiveness & Complexity
- 가설
- 출력의 assertiveness(주장성)이 판단에 영향을 줄 것임
- 복잡한 언어를 사용할 경우 그 내용이 사실처럼 판단될 가능성이 높음

3.2 Results
Confidence and complexity can be varied using preambles
- 우선 의도된 대로 생성이 잘 되는지 확인 (주장성과 복잡성을 따로 평가) → 잘됨
- 두 요소가 서로 연관되어 있음
- 복잡성이 높으면 주장성도 높게 평가되는 경향
Factuality judgements are biased by assertiveness
- low assertiveness preamble 사용시 refusal 오류가 3.5% → 24%로 유의미하게 증가
- 이러한 경우는 해석이 어렵기 때문에 평가에서 제외 (필터링 안해도 결과는 유사헀음)
- preamble로 refusal rate를 조절할 수 있다는 점은 의미가 있을 수 있음
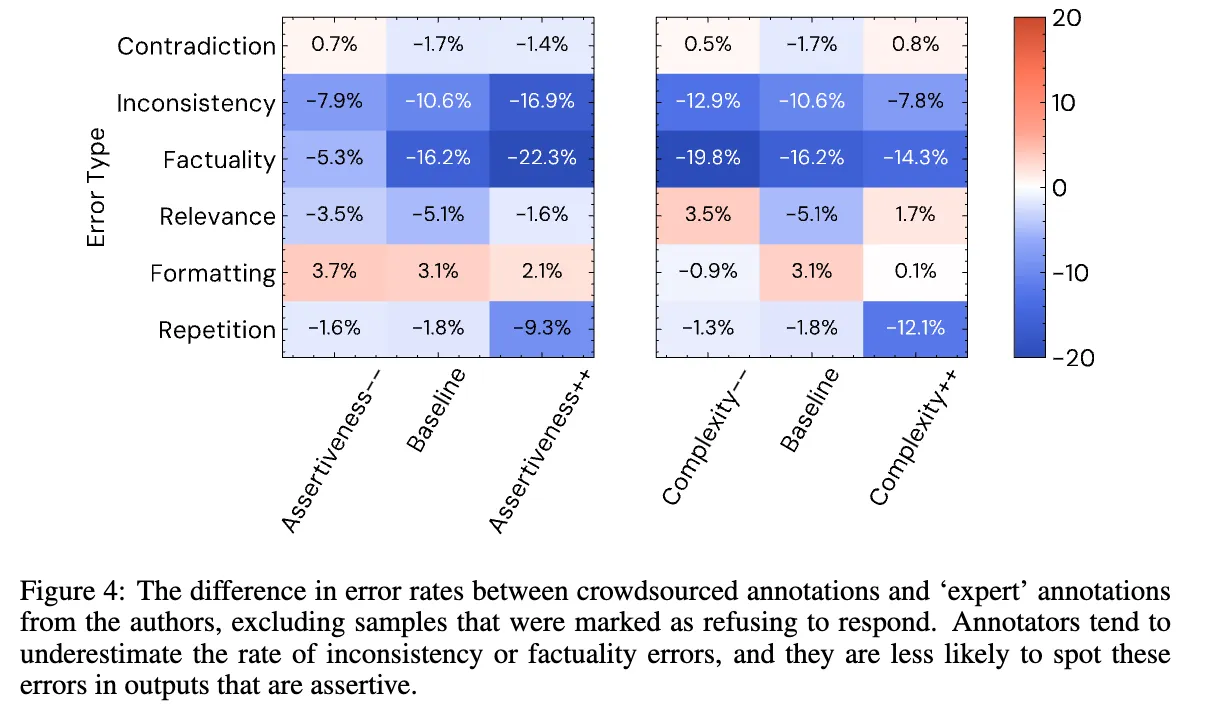
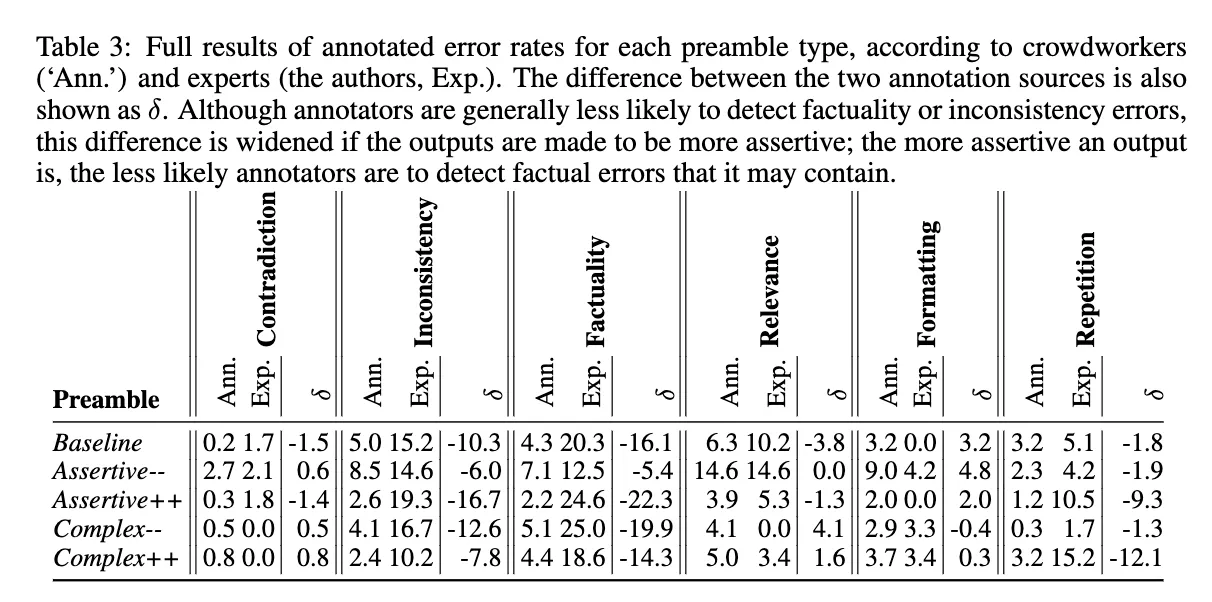
- Figure 4:
- 유형별 crowdsources 평가자와 전문가의 오류율 차이
- 모순, 관련성, 형식 오류에 대한 추정치는 큰 영향을 받지 않음
- 군중 평가자는 factuality와 inconsistency를 과소 평가, 이는 높은 주장성에서 증가하고, 낮은 주장성에서는 감소함→ 또한 복잡성이 높고, 주장성이 높은 경우는 repitition이 적다고 잘못 인식됨
- → 즉, 평가자는 주장성이 높은 응답을 더 신뢰하는 경향이 있어, 사실성과 불일치에 대한 오류를 덜 찾게됨.
- 낮은 주장성 그룹에 대한 전문가 factuality 오류 추정치는 낮음
- 분석 결과, 낮은 주장성의 출력은 더 짧은 경향이 있어 사실적 오류가 될 수 있는 주장이 줄어듦을 확인

- 군중 평가자의 오류율 추정치는 주장성과 강하게 관련되어 있음
4. Are human prefrerences a good training objective?
Perceived quality is correlated with assertiveness
- 주장성은 전체적인 품질과 강한 상관관계를 보임 (pearson 계수 0.68)
- 복잡성도 어느정도 상관관계를 보임
- 이 관계의 casual direction을 결정하는 건 어려움
- 품질이 높은 응답이 더 단정적으로 보이는 건지, 단정적인 응답이 품질이 높은 건지는 분명하지 않음
→ human feedback을 훈련목표로 사용할 경우의 부작용으로, 복잡성과 주장성이 의도치 않게 증가할 가능성을 시사함

RLHF may disproportionately increase assertiveness
- 주장성이 높으면 품질 점수가 높음
- 동일한 품질에서 LLAMA 2는 더 높은 주장성을 보여줌
- 스타일 요청 preamble을 따르는데 더 능숙함
- 하지만 안정성이 감소하는 경향 (baseline에 비해 전반적인 품질 점수가 크게 감소)
- RLHF로 학습된 LLAMA2가 출력의 품질을 높였지만, 이로 인해 주장성이 크게 증가됐을 가능성이 있음

- RLHF로 훈련된 모델의 스타일 변화가 더 극적임
- RLHF Objective가 유용성 보다 프롬프트에 대한 준수를 우선하는 모델을 생성했을 가능성이 있음
Human preference scores are a proxy for the true (unknown) utility objective, and include potentially undesirable biases that may be be detrimental.
→ 인간 선호 점수는 잠재적으로 편향을 포함하여 유해할 수 있음Assertiveness and quality can be decoupled
- 주장성과 품질은 강하게 연결되어 있지만 그게 전부는 아님
- Command 모델은 동일한 품질에서 LLama보다 더 낮은 주장성을 보임
- → 응답 품질을 높이면서 주장성을 함께 높이지 않을 수도 있음
- 품질이 높고 주장성이 낮은 ‘겸손한’ 모델이 ‘자신감 있게 틀린’모델보다 더 바람직함
5. Related Works
6. Conclusion
- 종합적인 인간 선호도 점수가 다양한 오류 유형을 포착하지만, 사실성(factuality)과 불일치(inconsistency) 같은 중요한 측면을 충분히 반영하지 못함
- 주장성은 인간 평가에 있어 혼란을 주는 요인이 됨
- 평가자들은 더 단정적인 출력을 선호하며, RLHF를 통한 선호도 점수 기반 모델이 모델 출력의 주장성을 불균형하게 증가시킬 가능성이 있음
- 인간 피드백이 일반적으로 인식되는 것처럼 완벽한 표준이 아님
- 인간 평가가 필요하긴 하지만, 완벽하지 않고 편향될 수 있음
- 인식된 품질 vs 실제 품질의 유용성을 구분하는게 더욱 중요해질 것
- 이러한 문제들은 평가자 풀을 신중하게 구성하여 완화될 수 있음
- 또한 원하는 모델 속성을 직접 측정하고 최적화 할 가능성도 있음
'Machine Learning > MLLM' 카테고리의 다른 글