-
Video Recap: Recursive Captioning for Hour-Long VideosMachine Learning/MLLM 2024. 8. 17. 22:29
https://sites.google.com/view/vidrecap
Video ReCap
Hierarchical Video Captioning Task
sites.google.com
https://arxiv.org/abs/2402.13250
Video ReCap: Recursive Captioning of Hour-Long Videos
Md Mohaiminul Islam, Ngan Ho, Xitong Yang, Tushar Nagarajan,Lorenzo Torresani, Gedas Bertasius
UNC Chapel Hill and Meta AI
Accepted by CVPR 2024
[Paper] [Code] [Dataset] [Demo] [HF]

Abstract: Video ReCap
- 기존 video 모델
- 길이 제한 ( 5-15 seconds )
- low-level visual concepts ( objects, scenes, atomic actions )
- recursive video captioning model ( 1 second ~ 2 hours )
- Ego4D-Hcap 데이터셋 ( # 8,267 )
1. Introduction
- 현실 세계 비디오의 대부분은 사람의 행동을 시간에 따라 세분화한 계층적 구조(Hierarchical information structure)를 가지고 있음
- atomic actions → intermediate activity steps → long term goal
- short-range cpatioing 방식은 atomic actions과 low-level visual detatil(object & scene)에 집중함
- 본 논문은 긴 비디오 영상에 대해 계층으로 이루어진 captions을 생성하는 task를 연구
- 심리학 & 사회인지론에 따르면, 인간의 행동은 내재적인 계층구조를 가지고 있다함
- atomic actions → intermediate steps → overal goals
1.1 Hierararchy
- short video clips ( several seconds )
- short-term captions
- low-level visual element ( objects, scenes, atomic actions )
- midium length video segement descriptions
- intermidate steps within broader activites (cooking recipe의 한 단계)
- short segments or sequences
- long-term humal goals
- 이벤트와 캐릭터간의 복잡한 관계(intricate relationships between events and characters)
- 영상의 포괄적인 목적 (overarching purpose behind the video)
1.2 Technical challenges
- 모델이 다양한 길이의 입력을 다룰 수 있어야함
- 기존 모델은 몇 분에 해당하는 고정 길이를 대상으로 만들어짐
- 긴 영상의 경우 중복이 많음, 필수적인 정보만 모을 수 있어야함
- 계층 구조를 이해해야하고, 서로 다른 계층 간의 시너지를 활용할 수 있어야함
1.3 Video ReCap
recursive video-language architecture
- short video clip 추출
- 이 후 계층에서는 이전 계층의 catpions을 입력으로 사용
- → modern LLM의 강력한 추론 능력을 활용할 수 있음
Curriculum learning scheme
- 점진적으로 계층 구조를 학습
LLM을 통한 pseudo-summary data 생성
1.4 Evaluation
Ego4D-HCap
https://arxiv.org/abs/2110.07058
https://ego4d-data.org/fig1.html 기반 으로 만듬
Egoscheme
- long-form video quesiton answering
3. Technical Apporach

3.1 Problem Overview
- Long-range videw seqeunces with T frames
- hierarchy = 1, 2, 3
- $Y^2_i$ = a person driving a car and parking it
- $Y^3_i$ → representing video content for the entire video input
- $Y^1_i$ = a person picks up an apple
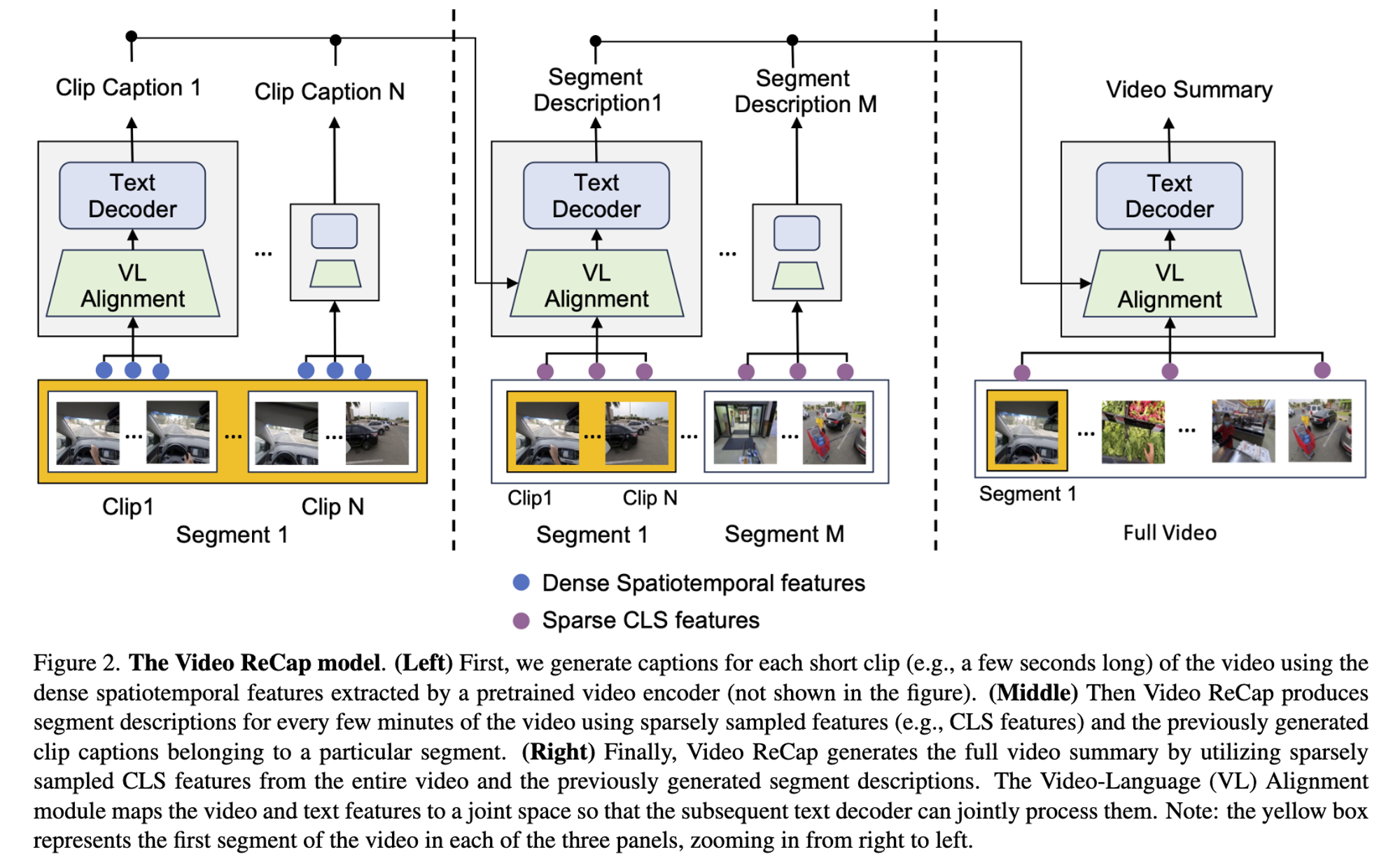
3.2 Recursive Video-Language Model
- Video Encoder + Video Language Alignment + Recursive Text Decoder
Video Encoder
- TimeSformer(ICML, 2021)
- $C$ video clips → features $x \in \mathbb{R}^{F\times H \times W \times D}$
- $F$ = # of frames
- short-clip frames = Dense spacetime features → identify low-level visual cues
- segment descriptions & Video = Global Features ( CLS features ) → High-level captions, reduce cost, capture global properties
Video-Language Alignment
- input : video features + captions generated in the previouse hierarchy
- output: fixed number of embeddings $Z$
- map the video and text features to the joint feature space → text decoder can jointly process both features ( BLIP-2와 같은 방식 )
- querying Transformer로는 DistilBERT 사용
- Concatenate video and text embeddings to get the joint embedding $Z$ ( *clip caption has no text features )
Recursive Text Decoder
- Pretrained GPT2
- trainable cross-attention blocks inside each transformer layer & freeze the remaining layers
( Flamingo, LAVILA 참고 )
Hierarchical Curriculum Learning

Challenge
- model must process videos of dramatically different input lengths
- Data imbalance ( short-term clop > video segment & long-range summaries )
- Exploiting the synergy between different hierarchy
Curriculum Learning
- motivation from classic studies of psychology( atomic ations → mid-level actions → goals )
→ herarchical organization of human perception of actions
3.4 Additional Supervision using Language Models

- Generate pseudo-caption annotations
- Finetune and LLM teacher to generate medium & Long summaries

4. Ego4D-HCap Dataset

Ego4D videos
- Longer than the traditional video
- goal driven + human activities at different hierarchy levels
- various scenarios ( cooking, gardening, assembly )
참고 https://ego4d-data.org/docs/data/annotations-schemas/
→ video-level summaires 8,267개 새로 annotate
🗺️ 번외: Ego4D Narrations

- Dense, timestampes description
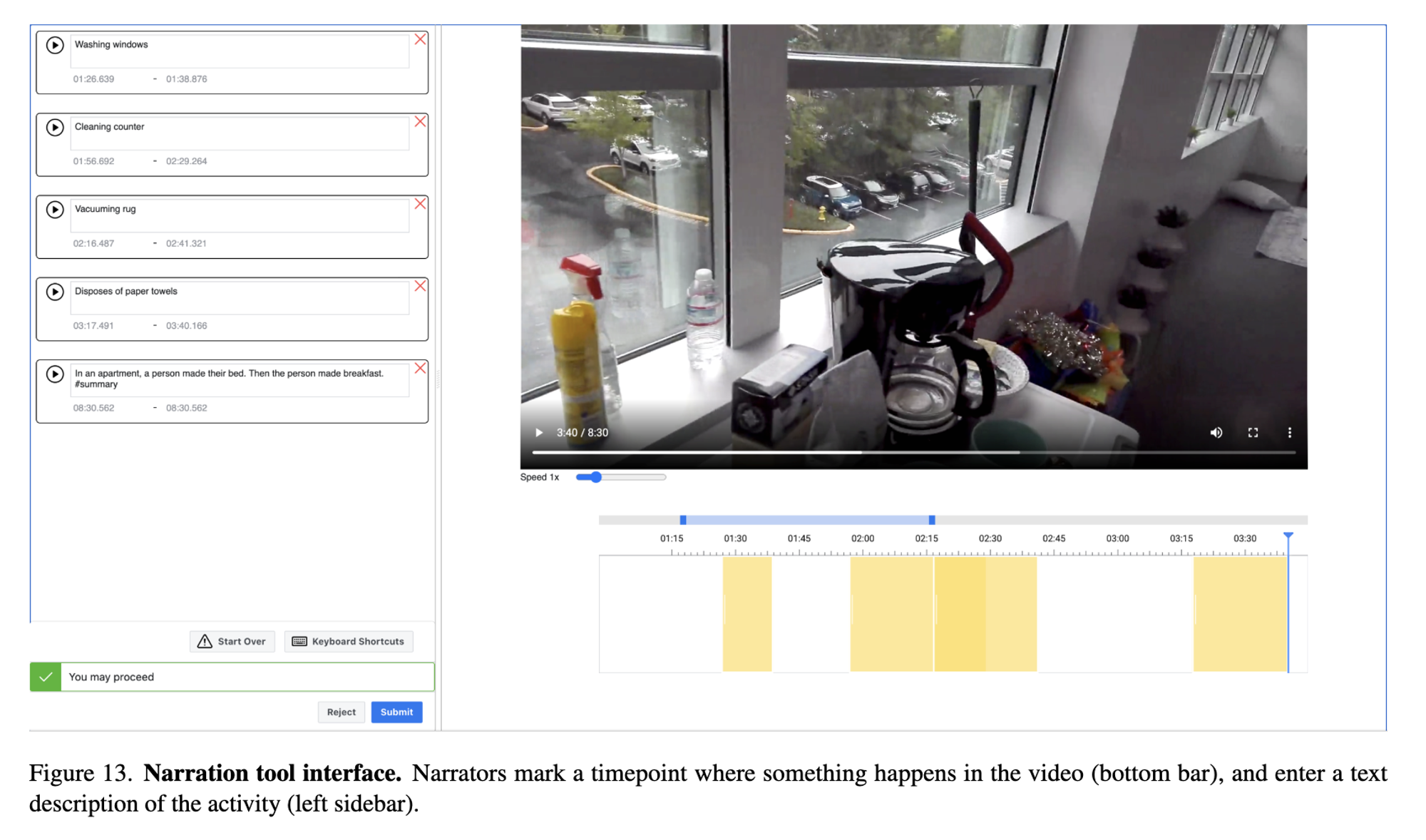
Ego4D: Around the World in 3,000 Hours of Egocentric Video 
- Label process
- 5 min clip을 두 명의 annotators에게 전달
- 5 min clip 전체 에 대한 1~3 문장 요약 → summary
- 특정한 상황 발생시 timestamp를 표시하여 이에 대한 short description 작성
- annotation prompt
Pretend as you watch this video that you are also talking to a friend on the phone, and you need to describe to your friend everything that is happening in the video. Your friend cannot see the video.
- Analysis
- 3.85M (3,850,000) sentences / 3,670 hours
- 영상마다 달라 실제로는 1분에 약 13.2개 정도 한다고 함
-
6. Results and Analysis

'Machine Learning > MLLM' 카테고리의 다른 글
- 기존 video 모델