-
Video Understanding Paper Summary (Data 중심)Machine Learning/MLLM 2024. 8. 17. 22:19
0. 전체 요약
Data Source Data Generation Post-Processing # Data
(for tuning)1. LLaVA Public Dataset
(COCO Images)ChatGPT-4 158K 2. MiniGPT-4 Public Dataset
(Conceptual Captions)Inital Pretrained Model ChatGPT-4
+manual3.5K 3. Valley Jukinmedia(73k)
+ llava(150k)
+ videochat(11k)ChatGPT-4 234k 4. VideoChat Public Dataset
(WebVid-10M)
+ LLaVA (2k r, 2k c)
+ MinGPT-4(3k d)ChatGPT-4 ChatGPT-4 18K 5. VideoChatGPT Public Dataset
(ActivityNet-200)Image Caption Model (BLIP, GRiT, Tag2Text) ChatGPT-3.5 100K 5. VideoChat2 Public Data + 1,2,4 ChatGPT-4 2M 1. LLaVA (Image)
1-1. Training
Stage 1 : Pre-training for feature alignment
- filter CC3M to 595K
Stage 2: fine-tuning instruction data
1-2. GPT-assisted Visual Instruction Data Generation
- Conversation (58K)

- Detailed description (23K)
- Complex Reasoning (77k)
- Example



2. Mini Gpt-4
https://arxiv.org/abs/2304.10592
2-1. Curating high-quality Alignment dataset
Stage 1. Inital aligned image-text-genration
- First pretraining stage로 input images의 comprehensive descriptions 생성
- 5,000 images From Conceptial Cpation Dataset.
Data Post-processing
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation.
Stage 2. Second-stage finetuning
- 3,500 out of 5,000 image 필터링
- manually 체크
3. Valley
https://arxiv.org/abs/2306.07207
3-1. Data Collection
Jukinmedia https://www.jukinmedia.com/

- 100k videos
- Description Length
- average : 40 words
- Longest : 100 words
- Video Duration
- average: 40 sec
- Longest: more than 5 min
- Description Length
Prompt for Instruction Data Generation

Prompt for generating instruction data of conversation

4. VideoChat
https://arxiv.org/abs/2305.06355
4-1. Traing data
- 25M vision-text pairs for one epoch fine-tuning
- CC12M, COCO Caption, Visual Genome, SBU Captions, CC3M, CC12M
- 18K data collection (tune for 3 epoch)
- 7k detailed video description, 4k video conversations
- We build a video-centric multimodal instruction data based on WebVid-10M
- 3K deatiled image descriptions from MiniGPT-4
- 2K image conversions. 2K image-reasoning from LLaVA
- 7k detailed video description, 4k video conversations

5. Video-ChatGPT
https://arxiv.org/abs/2306.05424
5.1 Dataset
- Video Instruction Data Generation
Instruction Data type
- Detailed descriptions
- Summarizations
- Can you provide a summary of the video?
- What are the main events in the video?
- Could you briefly describe the video content?
- Question-answer pairs
- What is the man doing in the video?
- What are the girls doing in the video?
- Describe the appearance of the motorbike
- Is the person riding the bike wearing a helmet?
- How does the person repair the car?
- Tasks that stimulate creativity or generation of new ideas
- Can you write a short poem inspired by the video?
- Create a short story that incorporates elements from the video.
- How would you turn the video into a fairy tale with a moral lesson?
- conversational tasks
1) Human-assisted Annotation (ActivityNet-200)
- 30,000 samples
- Levearage dataset containing video-caption pairs
- Utilize human annotators to enrich the original ground-truth annotations
- adding comprehensive information ( physical appearances & spatial and temporal localization)

2) Semi-automatic Annotation Farmework
- 70,000 samples

Semi-automatic Annotation Framework
- Frame Level Caption 데이터 생성
- Frame-level captions: BLIP-2
- Dense Captioning( with Object Detection ) : GRiT
- Frame Tag : Tag2Text ← noise 제거용
- Video-level caption 생성: GPT-3.5
- merge frame-level caption
- discard incosistent infomration
- Postprocessing: GPT-3.5
- Refines and optimizes the enriched annotations
- Create question-answer pairs from captions
- (detailed descriptions, summarizations, question-answer. piars, creativity, conversational tasks)
- Correction with Human Annotation
- For dataset curation
- Instructions 1: enrich the caption with comprehensive descriptions of the video, with specific attention to temporal and spatial details
- Instruction 2: neutralize the tone and biases
Key steps for high-quality data & mitigate noise
- High prediction threshold
- Specialized filtering mechanisms
extracting words from the frame-level captions that are within the predefined Tag2Text tags vocabulary and eliminates any captions that contain words not in the tags for a given frame
→ Tag2Text에 포함된 단어가 없는 BLIP, GRiT caption 삭제
- Merge frame-level captions
- use the GPT-3.5 model to generate singular coherent video-level caption
- direct GPT-3.5 to discard inconsistent information across frames
3) Tasks Example
- Video reasoning tasks
- Why is this video funny?
- What is strange about this video?
- Can you identify any safety hazards in this video?
- What is unusual about this video?
- Creative and generative tasks
- What is this video about?
- Generate a creative advertisement feature about this product that can be used on the product website
- Can you write a short poem inspired from the video
- Create a short fairy tale with a moral lesson inspired by the video
- Spatial understanding tasks
- Where is this video taken from? What place/landmark is shown in the video?
- Describe the video
- How many slices are on the baking sheet
- Temporal understanding tasks
- Describe the video in detail
- What is the video about?
- What happens after the match is over?
- Can you describe the process for cleaning a screen window as demonstrated in the video?
- Step-by-step describe the cooking recipe show in the video
- Action recognition tasks
- Describe the activity in the video
- Brefiely describe the video How may different horses are seen in the video?
- Video understanding and conversation tasks
- Describe the video in detail
- Waht is the main focus of the video
- What does the woman use to split the logs and how does she do it?
- What is the women wearing in the video?
- Describe the video
- Is there a flag in the background?
- Question-Answering tasks
- What is the video about?
- Can you describe the discus thrower’s technique in the video?
- What is the main challenge faced by the people on the boat?
- Waht are the people doing in the video?
- What activities are the woman and the dog engaged in the video?
GPT-Assisted Postprocessing
- GPT-3.5 to create question-answer pairs
- from the enriched and detailed captions
- includes 1. detailed descriptions 2. summarizations 3. question-answer pairs 4. tasks that stimilate creativity or the generation of new ideas 5. conversational tasks
5.2 Architecture

1) Benchmark: ActivitNet-200
2) Evaluation pipeline (GPT-3.5)
- Scale of 1-5
- Five aspects
- Correctness of Information
- We verify the accuracy of the generated text, ensuring it aligns with the video content and does not misinterpret or misinform.
- Detail Orientation
- We evaluate the depth of the model’s responses, looking for both completeness, meaning the model’s response covers all major points from the video, and specificity, denoting the inclusion of specific details rather than just generic points in the model’s response
- Contextual Understanding
- We assess the model’s understanding of the video’s context, checking if its responses align with the overall context of the video content.
- Temporal Understanding
- We examine the model’s grasp of the temporal sequence of events in the video when answering questions
- Consistency
- We evaluate the model’s consistency across different but similar questions or different sections of the video.
- Correctness of Information
6. VideoChat2 (MVBench)
https://arxiv.org/abs/2311.17005
6.1. Task List
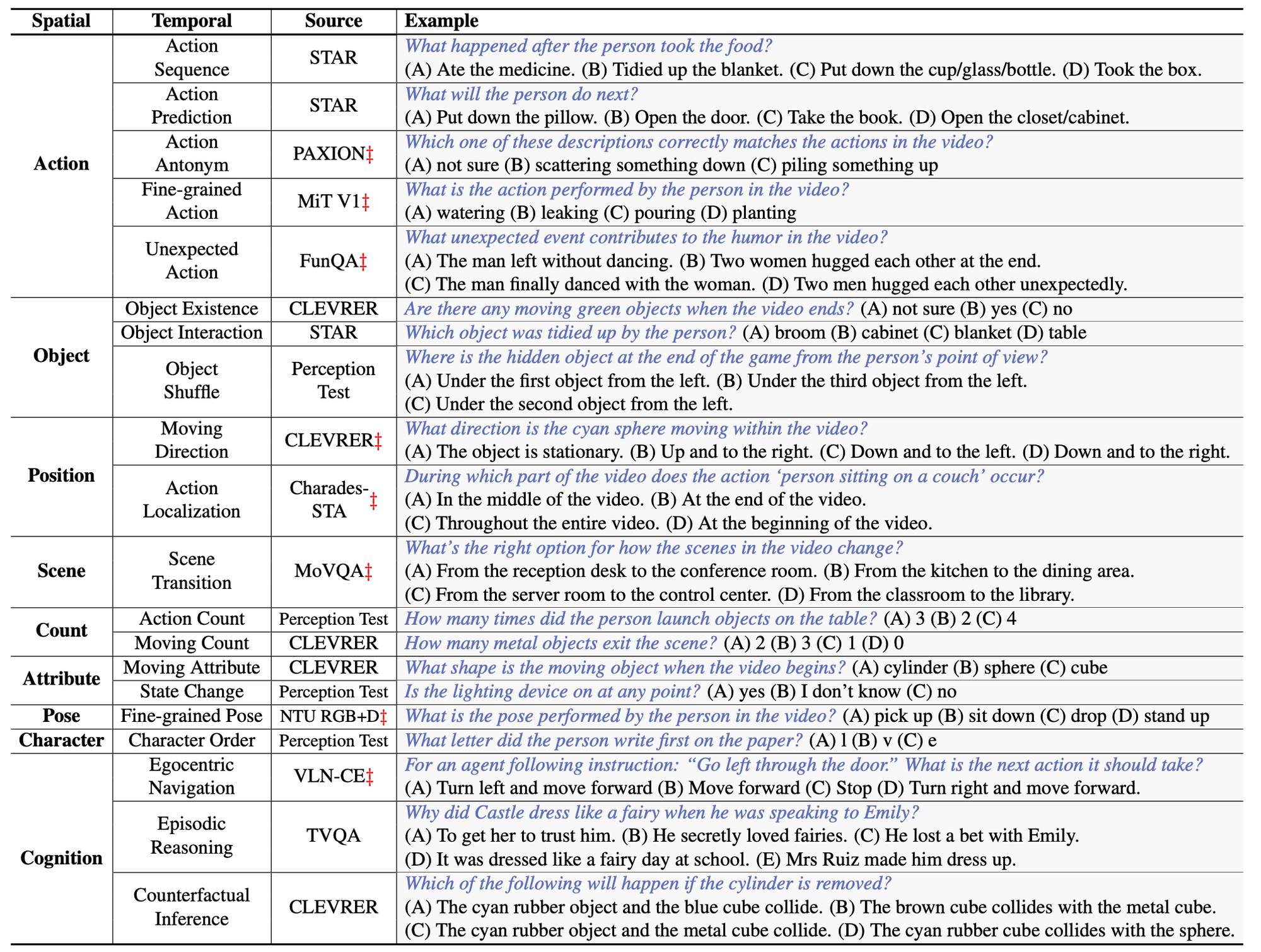
Public Dataset List
- 11 video datasets
6.2 Instruction-tuning data

6.3 Automatic Data Generation
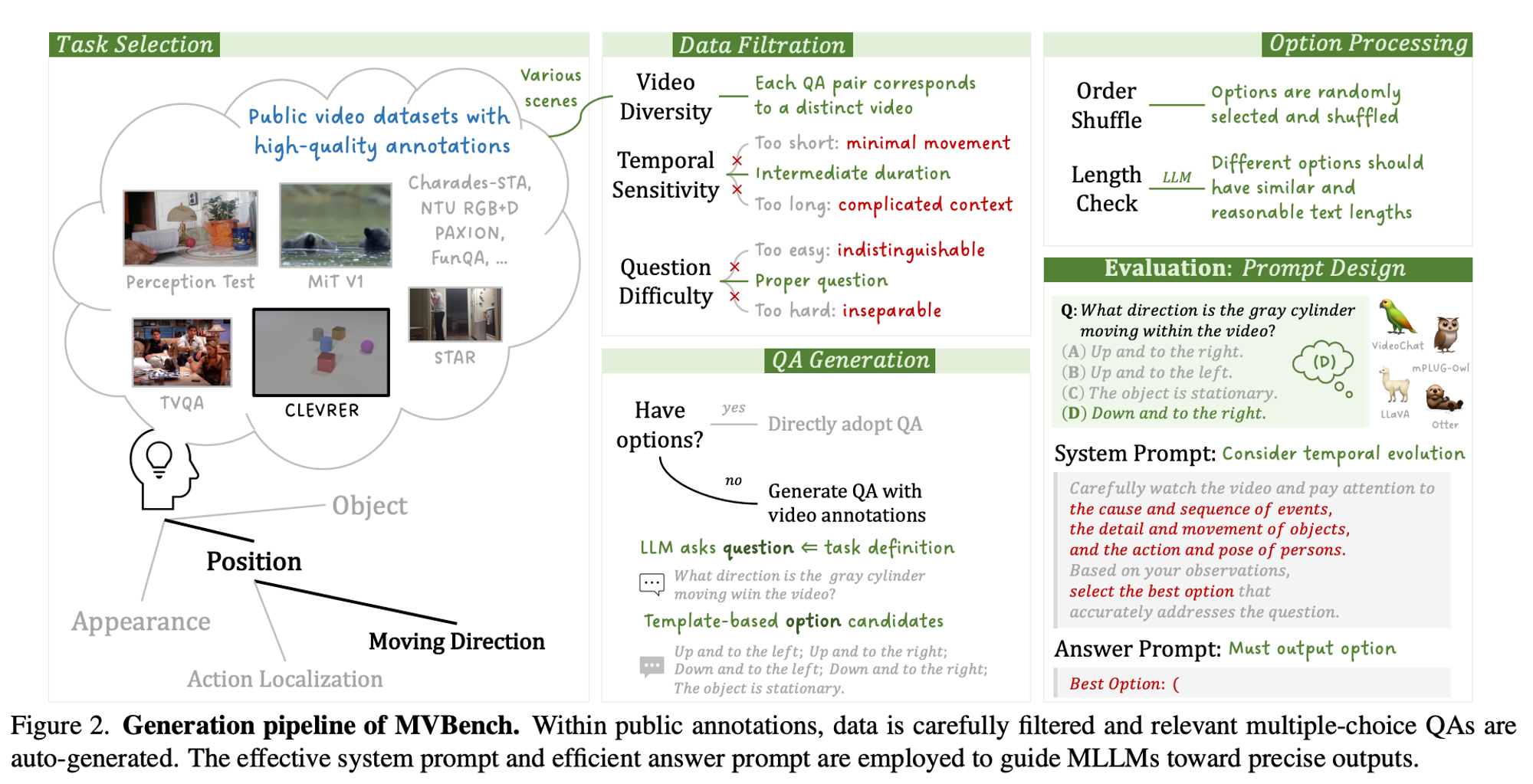
1) Data Filteration
- Video Diversity
- select 11 video dataests
- specrtrum of domains and scens / first-person to third-person / indoor to outdoor
- select 11 video dataests
- Temporal Sensitivity
- Too Short ❌ / Too Long ❌ → 5s ~ 35s
- Question Difficulty
- STAR: randomly sifting start / end point
- CLEVER: exclude questions that necessitate more than 10 conditions
2) QA Generation

- Template-Base Construction
- 기존 ground-truth 기반으로 생성 ( correct / opposite / not-sure )
- LLM-Based Generation
- open-ended QA를 muptiple-choice QA 로 변경
'Machine Learning > MLLM' 카테고리의 다른 글